
مهندس RAG
RAG Engineer
مهندس RAG سیستمهایی میسازد که مدلهای زبانی را با پایگاههای دانش خارجی ترکیب میکنند تا پاسخهای دقیق، بهروز و قابلاعتماد بدهند. با بازار ۳۸.۴٪ رشد سالانه و حقوق میانگین ۱۵۰,۰۰۰ دلار در آمریکا، RAG Engineering یکی از داغترین تخصصهای AI در سازمانهای enterprise است.
مقدمه و تعریف شغل
مهندس RAG (Retrieval-Augmented Generation) سیستمهایی میسازد که به جای تکیه صرف بر دانش درونی مدل زبانی، اطلاعات را از پایگاه دانش خارجی — اسناد، دیتابیس، وب — بازیابی میکنند و سپس LLM با این اطلاعات واقعی پاسخ میدهد. این تکنیک توهمزایی مدل را کاهش میدهد و پاسخها را بهروز و قابل ردیابی میکند.
RAG در سال ۲۰۲۰ توسط Patrick Lewis و تیم Meta AI معرفی شد (NeurIPS 2020). اما انفجار واقعی در ۲۰۲۳ بود — وقتی ChatGPT نشان داد LLM ها توهم دارند و سازمانها به راهحل نیاز داشتند. LlamaIndex و LangChain ابزارهای RAG را democratize کردند. در ۲۰۲۵، RAG در ۶۷٪ AI پروژههای enterprise استفاده میشود.
چه چیزی میسازید؟
مثالهای واقعی از خروجی کار یک مهندس RAG
chatbot اسناد سازمانی
سیستمی که از ۱۰,۰۰۰ صفحه سند شرکت پاسخ دقیق با ارجاع به منبع میدهد
جستجوی هوشمند دانش
موتور جستجویی که سوال را میفهمد نه فقط کلمهکلیدی میجوید
دستیار پشتیبانی مشتری
سیستمی که به ticket های قبلی و مستندات محصول دسترسی دارد و پاسخ دقیق میدهد
سیستم Q&A پزشکی و حقوقی
RAG روی پروندههای پزشکی یا قوانین حقوقی با ردیابی کامل منبع
کد assistant
سیستمی که codebase را index میکند و سوالات توسعهدهنده را با context واقعی پاسخ میدهد
تخصصهای مختلف مهندس RAG
این شغل یک عنوان واحد نیست — مسیرهای تخصصی متعددی دارد
RAG اسناد سازمانی
Enterprise Document RAG
پردازش PDF، Word، اسلاید — ترکیب OCR و RAG برای اسناد حجیم
RAG چندوجهی
Multimodal RAG
بازیابی از تصویر، نمودار، جدول — نه فقط متن
گراف RAG
GraphRAG
استفاده از knowledge graph برای بازیابی با درک روابط — Microsoft GraphRAG
RAG بلادرنگ
Real-time RAG
بازیابی از دادههای زنده: خبر، قیمت سهام، ایمیل جدید
تفاوت با شغلهای مشابه
کجا این شغل تمام میشود و شغل دیگری شروع میشود؟
مهندس LLM روی مدل زبانی تمرکز دارد: fine-tuning، evaluation، inference. مهندس RAG روی pipeline بازیابی است: chunking، embedding، vector search، reranking — مدل فقط قدم آخر است.
Search Engineer سنتی با keyword و BM25 کار میکند. RAG Engineer semantic search با embedding vectors را با LLM ترکیب میکند — پاسخ تولید میکند نه فقط لینک برمیگرداند.
Data Engineer pipeline انتقال و ذخیره داده میسازد. RAG Engineer pipeline پردازش، embedding و بازیابی برای مصرف LLM میسازد — focus روی معنا و relevance است نه حجم.
تأثیر در صنایع مختلف
مهندس RAG در همه صنایع مشغول به کار است — نه فقط شرکتهای فناوری
حقوقی
Harvey AI از RAG برای research پروندههای حقوقی استفاده میکند — ۹۷٪ Am Law 100 مشتری آناند
سلامت
RAG روی پروندههای بیمار و پروتکلهای درمانی — تصمیمگیری پزشکی با ارجاع دقیق
مالی
تحلیل گزارشهای مالی، رگولاتوری و اخبار بازار با ردیابی دقیق منبع
آموزش
دستیار آموزشی که از متن درسی پاسخ میدهد نه اطلاعات عمومی
نرمافزار
code assistant که codebase شرکت را میفهمد — نه فقط GitHub Copilot عمومی
تصورات غلط رایج
قبل از تصمیمگیری، این باورهای اشتباه را بشناسید
RAG فقط یعنی embedding + vector search
RAG یک pipeline پیچیده است: chunking استراتژیک، embedding انتخابی، hybrid search، reranking، context compression، و evaluation. یک RAG ساده در production شکست میخورد.
با fine-tuning دیگر نیازی به RAG نیست
Fine-tuning رفتار مدل را عوض میکند اما دانش خارجی نمیدهد. RAG برای اطلاعات بهروز، اسناد خصوصی و ردیابی منبع ضروری است. بهترین سیستمها از هر دو استفاده میکنند.
context window بزرگتر، RAG را منسوخ میکند
هزینه inference با context طولانی بسیار بالاتر از vector search است. RAG برای private data، real-time update و source citation جایگزینناپذیر باقی میماند.
یک روز کاری واقعی
در هر سطح روز کاری چه شکلی است؟
جونیور
ساخت pipeline های RAG ساده با LangChain، آزمایش chunking strategy های مختلف، debug کردن relevance ضعیف. بخش زیادی از وقت صرف data preprocessing و index سازی میشود.
- ◆پیادهسازی basic RAG با LangChain یا LlamaIndex
- ◆آزمایش chunk size و overlap مختلف
- ◆ساخت embedding pipeline برای PDF و Word
- ◆اجرای RAGAS برای ارزیابی کیفیت
- ◆debug کردن مشکلات retrieval
میدلول
طراحی advanced RAG با hybrid search و reranking، بهینهسازی latency، پیادهسازی evaluation framework، کار با اسناد پیچیده مثل PDF با جدول و نمودار.
- ◆پیادهسازی hybrid search (BM25 + semantic)
- ◆ادغام reranker (Cohere Rerank یا BGE)
- ◆بهینهسازی vector DB برای latency
- ◆ساخت evaluation pipeline اتوماتیک
- ◆پردازش document های multimodal
سینیور
طراحی RAG platform قابل scale برای سازمان، تصمیمگیری درباره معماری (GraphRAG vs flat)، تعریف استاندارد evaluation، mentoring تیم.
- ◆طراحی RAG architecture برای ۱۰۰+ منبع داده
- ◆انتخاب و بهینهسازی vector DB در مقیاس
- ◆تعریف KPI و evaluation framework
- ◆review معماری و code review
- ◆همکاری با product برای use case جدید
مسئولیتها و وظایف
مسئولیتهای اصلی
وظایف روزانه و مهارتهای مورد نیاز در این شغل
- ◈طراحی و پیادهسازی pipeline های RAG برای پروژههای enterprise
- ◈انتخاب و پیکربندی vector database مناسب (Pinecone، Weaviate، Milvus، Qdrant)
- ◈طراحی chunking strategy بهینه برای انواع اسناد مختلف
- ◈پیادهسازی hybrid search با ترکیب BM25 و semantic search
- ◈ادغام reranking برای بهبود دقت بازیابی
- ◈ارزیابی کیفیت RAG با RAGAS و معیارهای سفارشی
- ◈بهینهسازی latency و هزینه در سیستمهای production
- ◈مستندسازی معماری و best practice برای تیم
- ◈همکاری با domain expert برای تعریف use case های RAG
مهارتهای مورد نیاز
مهارتهای فنی، نرم و حوزهای که یک مهندس RAG موفق به آنها نیاز دارد
مهارتهای فنی
فریمورکهای اصلی برای ساخت RAG pipeline — ابزار اول هر RAG Engineer
Pinecone، Weaviate، Milvus، Qdrant، Chroma — ذخیره و جستجوی embedding ها
OpenAI ada-002 و text-embedding-3، Cohere Embed، BGE — تبدیل متن به vector
زبان اصلی RAG Engineering — async، data processing، API integration
fixed-size، recursive، semantic، parent-child chunking برای انواع اسناد
ترکیب BM25 keyword search با semantic search برای بهترین نتیجه
Cohere Rerank، BGE Reranker، FlashRank — بهبود دقت بعد از retrieval اولیه
RAGAS، TruLens، DeepEval — سنجش faithfulness، relevance، completeness
Microsoft GraphRAG، Neo4j — بازیابی مبتنی بر knowledge graph
HyDE، FLARE، CRAG، Self-RAG — تکنیکهای پیشرفته برای بهبود کیفیت
مهارتهای نرم
تشخیص علت ضعف retrieval و طراحی راهحل — debugging ذهنی بالاست
درک نیاز کاربر از پاسخ — نه فقط metric فنی، بلکه تجربه واقعی
نوشتن مستندات pipeline، تصمیمات معماری و راهنمای evaluation
دانش حوزهای
مفاهیم BM25، TF-IDF، precision/recall، NDCG — پایه جستجو
tokenization، embedding، semantic similarity — درک پایه
AWS Bedrock، Azure OpenAI، GCP Vertex AI — deploy RAG در cloud
نقشه راه و مسیر آموزشی
نقشه راه تبدیل شدن به مهندس RAG
این مسیر گام به گام شما را از صفر تا حرفهای هدایت میکند.
پایههای Python و NLP
آشنایی با Python async، API call به OpenAI/Anthropic، مفاهیم embedding و similarity.
Vector Database و Embedding
کار عملی با vector databases، آزمایش embedding model های مختلف، index کردن ۱۰۰ PDF.
RAG Pipeline با LangChain و LlamaIndex
ساخت RAG pipeline کامل، آزمایش chunking strategy های مختلف، اندازهگیری کیفیت با RAGAS.
Advanced RAG و Production
پیادهسازی hybrid search، ادغام reranker، deploy روی cloud، monitoring با Langfuse.
منابع پیشنهادی
تخصص پیشرفته
GraphRAG، Multimodal RAG، تکنیکهای HyDE و FLARE، طراحی RAG platform در مقیاس سازمانی.
ابزارها و استک فنی
ابزارهایی که هر مهندس AI باید بشناسد، دستهبندیشده بر اساس اولویت
فریمورکهای RAG
Vector Databases
Embedding Models
Reranking
Evaluation و Monitoring
مسیر پیشرفت شغلی
از جونیور تا Staff Engineer — چه مهارتهایی نیاز دارید و چه درآمدی انتظار داشته باشید
RAG Developer / جونیور
۰-۲ سال
~$100K
میانگین سالانه (آمریکا)
ساخت RAG pipeline ساده، کار با LangChain یا LlamaIndex، آزمایش chunking
RAG Engineer
۲-۴ سال
~$155K
میانگین سالانه (آمریکا)
طراحی advanced RAG با hybrid search و reranking، بهینهسازی production
Senior RAG Engineer
۴-۷ سال
~$215K
میانگین سالانه (آمریکا)
معماری RAG platform، تعریف evaluation standard، mentoring
Staff AI Engineer / RAG Architect
۷+ سال
~$295K
میانگین سالانه (آمریکا)
RAG platform در مقیاس سازمانی، تصمیمگیری فنی استراتژیک
چالشها و جنبههای منفی
واقعیتهایی که کمتر در آگهیهای شغلی میبینید — قبل از ورود بدانید
پیچیدگی Chunking
عمومیانتخاب اشتباه chunk size یا strategy کل سیستم را خراب میکند. متن کوتاه context کم دارد، متن بلند noise ایجاد میکند. جدولها، نمودارها و فهرستها باید متفاوت از متن ساده پردازش شوند — هیچ راهحل جهانی وجود ندارد.
کیفیت Retrieval در سوالات پیچیده
عمومیسوالات چند بخشی یا نیازمند inference از چند منبع، retrieval را دشوار میکنند. Multi-hop retrieval و query decomposition مهارت پیشرفتهای است.
Hallucination علیرغم Context
عمومیحتی با context درست، مدل گاهی اطلاعات را نادرست منعکس میکند. faithfulness evaluation و prompt engineering دقیق الزامی است.
Latency در Production
شرکت بزرگRAG pipeline چندین مرحله دارد: embedding query، vector search، reranking، LLM call. هر مرحله latency اضافه میکند. در سیستمهای real-time، بهینهسازی هر میلیثانیه اهمیت دارد.
بهروزرسانی پایگاه دانش
شرکت بزرگوقتی اسناد تغییر میکنند، باید index بهروز شود. استراتژی incremental indexing، مدیریت deletion و versioning — نادیده گرفتن اینها منجر به پاسخهای منقضی میشود.
هزینه Embedding در مقیاس
استارتاپindex کردن میلیونها document هزینه embedding قابلتوجهی دارد. انتخاب بین API embedding (گرانتر، بهتر) و self-hosted (ارزانتر، نگهداری بیشتر) یک تصمیم معماری مهم است.
حقوق و بازار کار جهانی
حقوق جهانی مهندس RAG
میانگین حقوق سالانه بر اساس تجربه در کشورهای مختلف
| کشور | میانه | ارز |
|---|---|---|
🇺🇸ایالات متحده (سینیور) | $215,000 | USD |
* ارقام سالانه و تقریبی هستند و بر اساس میانگین بازار در سال ۲۰۲۵ محاسبه شدهاند.
چگونه از صفر شروع کنیم
برنامه گامبهگام برای ورود به مهندسی هوش مصنوعی
ماه ۱-۲: پایهها
Python async، API call به OpenAI، مفاهیم embedding و cosine similarity. پروژه: ساخت script که PDF میخواند و با LangChain naive RAG از آن سوال میپرسد.
ماه ۳: Vector Database
Chroma برای local، بعد Pinecone برای cloud. index کردن ۵۰۰ document، آزمایش embedding های مختلف.
ماه ۴-۵: Advanced RAG
اضافه کردن reranker، آزمایش hybrid search، اندازهگیری با RAGAS. پروژه: chatbot روی ۱۰۰۰ صفحه مستندات — faithfulness بالای ۸۰٪.
ماه ۶: Portfolio و Job Search
یک RAG project کامل روی GitHub با README حرفهای. وبلاگ درباره تجربهات بنویس. apply برای junior RAG Engineer یا AI Engineer.
پروژههای پیشنهادی برای رزومه
Document Q&A با Citation
مبتدیسیستم RAG که از PDF های آپلودشده سوال پاسخ میدهد و منبع دقیق (صفحه و پاراگراف) را ذکر میکند.
Advanced RAG با Hybrid Search
متوسطpipeline کامل با BM25 + semantic search + Cohere Rerank + RAGAS evaluation. مقایسه naive RAG vs advanced RAG.
Codebase Chat
پیشرفتهسیستم RAG روی یک codebase بزرگ — parse توابع و class ها، جستجو بر اساس semantic meaning کد، پاسخ سوال developer.
مثالهای واقعی و Case Studies
داستانهای واقعی از مهندسانی که در این حوزه تأثیرگذار بودهاند
Patrick Lewis
دکترا در NLP از University College London، همزمان research scientist در Facebook AI Research. پیشینه در information retrieval و knowledge-intensive NLP.
در ۲۰۲۰، مقاله RAG را در NeurIPS publish کرد که تکنیک Retrieval-Augmented Generation را رسمی کرد. این مقاله پایه تمام سیستمهای RAG امروزی است. اکنون تیم RAG را در Cohere رهبری میکند.
ترکیب Information Retrieval کلاسیک با LLM نوین یک breakthrough واقعی بود. مهارت در هر دو حوزه — search و NLP — ارزش استثنایی ایجاد کرد.
Jerry Liu
فارغالتحصیل Princeton، ML Engineer در Quora و Research Scientist در Uber AI. کار روی ML systems در تیمهای production.
در اکتبر ۲۰۲۲، در یک hackathon داخلی LlamaIndex را ساخت. تا مارس ۲۰۲۳، شرکت LlamaIndex را co-found کرد. این فریمورک اکنون محبوبترین ابزار RAG برای data-intensive applications است.
یک hackathon project که یک pain point واقعی را حل میکند میتواند به شرکت تبدیل شود. درک عمیق از چالشهای production ML، بهترین راهنما برای ساخت ابزار است.
Douwe Kiela
دکترا از University of Cambridge، researcher در Facebook AI Research در کنار Patrick Lewis. تخصص در multimodal learning و information retrieval.
یکی از co-author های اصلی مقاله RAG (NeurIPS 2020). سپس به Hugging Face رفت و روی dataset ها و evaluation کار کرد. در ۲۰۲۳ Contextual AI را تأسیس کرد — شرکتی که RAG-specific LLM برای enterprise میسازد و بالای ۱۰۰ میلیون دلار funding جذب کرده.
تحقیق academic درباره تکنیکی که خودت اختراع کردی، میتواند پایه یک شرکت باشد. درک عمیق از محدودیتهای تکنیک، roadmap کسبوکار میشود.
نمونه آگهی استخدام واقعی + تحلیل
یک آگهی واقعی از شرکت فعال در حال استخدام، با تحلیل هر بخش
Member of Technical Staff — Retrieval-Augmented Generation (RAG)
تحلیل نیازمندیها
Bachelor's in CS + 6 years experience (or Master's + 6 years)
تجربه عملی ترجیح داده میشود بر مدرک. اگر ۴-۵ سال تجربه قوی RAG production داری، apply کن — Microsoft به outcome اهمیت میدهد.
ضروری4+ years building APIs and pipelines for large-scale products
منظور soft skills مهندسی نرمافزار است — REST API، microservices، CI/CD. RAG Engineer باید engineer خوب هم باشد.
ضروریExperience building and deploying LLM applications at scale
portfolio با RAG system که واقعاً deploy شده حیاتی است. side project با ۱۰۰K document کافی نیست — باید production traffic داشته باشد.
ضروریSearch, embeddings, retrieval, ranking, and RAG for Copilot memory
این دقیقاً core RAG stack است. Pinecone یا Weaviate، OpenAI embeddings، reranking با Cohere — اینها مهارتهایی هستند که باید بلد باشی.
ضروریAzure cloud experience
Azure Cognitive Search، Azure OpenAI Service، Azure Cosmos DB — دانستن Azure ecosystem یک امتیاز بزرگ است. تجربه AWS Bedrock نیز transferable است.
مهمتحلیل مسئولیتها
Design and build large-scale Copilot memory and personalization systems
این RAG در مقیاس Microsoft Copilot است — میلیونها کاربر. مهارت در distributed vector search و caching اهمیت دارد.
Leverage search, embeddings, retrieval, ranking, and RAG techniques
تمام pipeline RAG را باید بدانی: از document ingestion تا query rewriting تا response generation.
نتیجهگیری کلی
Microsoft حقوق $139,900-$274,800 پایه پرداخت میکند (تا $304,200 در SF/NYC). تمرکز روی production RAG at scale، Azure stack و software engineering fundamentals قوی — نه فقط Python notebook.
آینده و روندها
پیشبینی ۵–۱۰ ساله و مهارتهایی که باید یاد بگیرید
بازار RAG از ۱.۹۴ میلیارد دلار در ۲۰۲۵ به ۹.۸۶ میلیارد دلار تا ۲۰۳۰ میرسد — CAGR ۳۸.۴٪
منبع: MarketsandMarkets, 2025
مهارتهای نوظهور که باید یاد بگیرید
پیشبینیهای آینده
GraphRAG و knowledge graph به mainstream تبدیل میشوند — درک روابط بین موجودیتها دقت را چند برابر میکند
Multimodal RAG که از تصویر، ویدیو و جدول بازیابی میکند به استاندارد enterprise تبدیل میشود
Agentic RAG — ترکیب RAG با agent که multi-hop retrieval خودمختار انجام میدهد — غالب میشود
بازار ۹.۸۶ میلیارد دلاری نیاز به ۱۰۰,۰۰۰+ متخصص RAG دارد — تقاضا از عرضه پیشی میگیرد
با بلندتر شدن context window مدلهای زبانی (Gemini 1M token)، برخی تصور میکنند RAG منسوخ میشود. اما هزینه inference در context طولانی بسیار بالاتر از vector search است. RAG برای private data، real-time update و source citation جایگزینناپذیر باقی میماند. تخصص RAG Engineer به GraphRAG، multimodal و agentic RAG تکامل مییابد — نه منسوخ میشود.
ویدیوهای آموزشی
یک روز در زندگی یک RAG Engineer
ویدیوهای واقعی از متخصصان این حوزه که روزانه چه کارهایی انجام میدهند
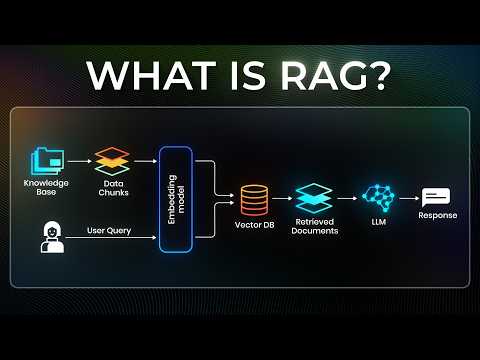
RAG Explained For Beginners
KodeKloud

LLMs — How ChatGPT works & What is RAG? | Retrieval-Augmented Generation Explained 🔥
CodeWithHarry

Advanced RAG techniques for developers
Google Cloud Tech

LangChain Explained in 13 Minutes | QuickStart Tutorial for Beginners
Rabbitmetrics

What is RAG ? | Completely Explained in 15 Minutes
Apna College

What is Agentic AI and How Does it Work?
codebasics