
مهندس پردازش زبان طبیعی
NLP Engineer
مهندس پردازش زبان طبیعی سیستمهایی میسازد که زبان انسانی را میفهمند، تحلیل میکنند و تولید میکنند — از chatbot و ترجمه ماشینی تا تحلیل احساسات و خلاصهسازی خودکار. با رشد ۳۶٪ تا ۲۰۳۵ و حضور در ۱۹.۷٪ آگهیهای شغلی AI، NLP پرتقاضاترین مهارت هوش مصنوعی در بازار کار است.
مقدمه و تعریف شغل
مهندس NLP (Natural Language Processing Engineer) متخصصی است که الگوریتمها و مدلهای یادگیری ماشین طراحی میکند تا کامپیوتر بتواند متن و گفتار انسانی را پردازش، درک و تولید کند. این حوزه در تقاطع زبانشناسی، آمار و یادگیری عمیق قرار دارد.
NLP از دهه ۱۹۵۰ با قوانین دستوری دستی شروع شد. انتشار paper «Attention is All You Need» در ۲۰۱۷ و معماری Transformer، انقلابی ایجاد کرد که به BERT (۲۰۱۸)، GPT-2، GPT-3 و در نهایت ChatGPT منجر شد. امروز NLP پایه تمام هوش مصنوعی مکالمهای است و تقریباً هر محصول دیجیتال به شکلی از آن استفاده میکند.
چه چیزی میسازید؟
مثالهای واقعی از خروجی کار یک مهندس پردازش زبان طبیعی
چتبات و دستیار هوشمند
ChatGPT، Claude، Gemini — سیستمهای مکالمهای که درک زبان طبیعی دارند
ترجمه ماشینی
Google Translate، DeepL — ترجمه بین ۱۰۰+ زبان با کیفیت نزدیک به انسانی
تحلیل احساسات
تحلیل نظرات مشتریان، پایش برند در شبکههای اجتماعی
جستجوی معنایی
موتور جستجوی Google، جستجوی داخلی Notion و Confluence
خلاصهسازی خودکار
خلاصه اخبار، summarize meeting، تولید abstract علمی
تخصصهای مختلف مهندس پردازش زبان طبیعی
این شغل یک عنوان واحد نیست — مسیرهای تخصصی متعددی دارد
هوش مصنوعی مکالمهای
Conversational AI
طراحی chatbot و dialog system — داغترین زیرحوزه در پی ChatGPT
ترجمه ماشینی
Machine Translation
مدلهای sequence-to-sequence برای ترجمه بین زبانها
استخراج اطلاعات
Information Extraction
NER، relation extraction، knowledge graph ساخت از متن ساختارنیافته
NLP چندزبانه
Multilingual NLP
مدلهایی که همزمان چند زبان را پشتیبانی میکنند — تقاضا برای فارسی، عربی، هندی رو به رشد
تفاوت با شغلهای مشابه
کجا این شغل تمام میشود و شغل دیگری شروع میشود؟
مهندس DL با تمام modality های داده (تصویر، صوت، متن) کار میکند. مهندس NLP فقط در متن و زبان تخصص دارد و دانش زبانشناسی، tokenization و language model عمیقتری لازم دارد.
مهندس LLM با مدلهای بزرگ از پیش آموزشدیده کار میکند (GPT، Claude، Llama). مهندس NLP طیف گستردهتری دارد: از regex و classical NLP تا fine-tuning مدلهای کوچکتر برای task های خاص.
Data Scientist روی دادههای structured (جدول، عدد) کار میکند. مهندس NLP با دادههای unstructured متنی کار میکند و نیاز به دانش عمیق در پردازش متن، tokenization و language model دارد.
تأثیر در صنایع مختلف
مهندس پردازش زبان طبیعی در همه صنایع مشغول به کار است — نه فقط شرکتهای فناوری
حقوقی
بررسی خودکار قراردادها، جستجو در پروندههای حقوقی — صرفهجویی ۶۰٪ در زمان luậtخوانی
بهداشت
استخراج اطلاعات از پروندههای پزشکی، تشخیص بیماری از علائم بیمار بیانشده
مالی
تحلیل اخبار و گزارشهای مالی برای trading، تشخیص کلاهبرداری از ارتباطات
آموزش
ارزیابی خودکار مقاله، feedback بلادرنگ به زبانآموز، خلاصهسازی کتابهای درسی
خدمات مشتری
chatbot که ۸۰٪ سوالات رایج را بدون دخالت انسانی پاسخ میدهد
تصورات غلط رایج
قبل از تصمیمگیری، این باورهای اشتباه را بشناسید
NLP یعنی فقط API Call به ChatGPT
استفاده از API محصول نهایی است، نه مهندسی NLP. مهندس NLP مدل میسازد، fine-tune میکند، tokenizer طراحی میکند، pipeline ارزیابی مینویسد و مدل را در production مستقر میکند. کار واقعی پشت پرده OpenAI است.
باید زبانشناسی خوانده باشی
زبانشناسی مفید است اما ضروری نیست. اکثر مهندسان NLP از CS، مهندسی نرمافزار یا ریاضیات میآیند. درک پایهای از morphology و tokenization که در طول کار یاد میگیری کافی است.
NLP فقط با انگلیسی کار میکند
مدلهای چندزبانه مثل mBERT و XLM-RoBERTa بیش از ۱۰۰ زبان را پشتیبانی میکنند. بازار NLP فارسی، عربی و هندی بهشدت کمرقیب و پرتقاضاست — فرصت واقعی برای ایرانیها.
یک روز کاری واقعی
در هر سطح روز کاری چه شکلی است؟
جونیور
پیادهسازی pipelineهای NLP با HuggingFace، آمادهسازی dataset، fine-tuning مدلهای موجود و ارزیابی نتایج. بخش بزرگی از روز صرف data cleaning و text preprocessing میشود.
- ◆tokenization و پاکسازی متن خام
- ◆fine-tuning BERT برای sentiment analysis
- ◆محاسبه F1-score و confusion matrix
- ◆آزمایش hyperparameter های مختلف
- ◆خواندن paper های جدید HuggingFace
میدلول
طراحی pipeline کامل NLP، انتخاب معماری مناسب برای use case، بهینهسازی inference و همکاری با تیم product.
- ◆طراحی architecture برای task جدید (NER، QA، summarization)
- ◆ارزیابی مدلهای مختلف و benchmark مقایسهای
- ◆بهینهسازی latency با ONNX یا quantization
- ◆ساخت evaluation framework برای مدلهای زبانی
- ◆code review و mentoring
سینیور
تعریف استراتژی NLP شرکت، هدایت تیم، تصمیمگیری build vs buy برای هر component.
- ◆تعریف roadmap تکنیکال NLP platform
- ◆ارزیابی foundation models برای fine-tuning
- ◆هدایت پروژه ساخت language model اختصاصی
- ◆همکاری با product درباره use case های NLP
- ◆نمایندگی تیم در کنفرانسهای ACL یا EMNLP
مسئولیتها و وظایف
مسئولیتهای اصلی
وظایف روزانه و مهارتهای مورد نیاز در این شغل
- ◈طراحی و پیادهسازی pipeline های NLP برای task های تعریفشده کسبوکار
- ◈fine-tuning و adaption مدلهای زبانی پیشآموزشدیده برای use case اختصاصی
- ◈طراحی dataset، annotation و ارزیابی کیفیت داده
- ◈ارزیابی مدل با معیارهای مناسب (F1، BLEU، ROUGE) و تحلیل خطاها
- ◈بهینهسازی inference برای latency و throughput در production
- ◈مستندسازی مدلها، تصمیمات فنی و نتایج آزمایشها
- ◈پایش دقت مدلهای production و رفع distribution shift
- ◈همکاری با تیم محصول برای ترجمه نیازمندی به task فنی قابل اندازهگیری
مهارتهای مورد نیاز
مهارتهای فنی، نرم و حوزهای که یک مهندس پردازش زبان طبیعی موفق به آنها نیاز دارد
مهارتهای فنی
NLTK، spaCy، HuggingFace Transformers. Python زبان اصلی است. spaCy برای کارهای سریع production، HuggingFace برای fine-tuning.
درک معماری Transformer، self-attention و positional encoding. آشنایی با خانواده BERT (RoBERTa، DeBERTa) و GPT.
Transformers، Datasets، PEFT، Evaluate — اکوسیستمی که در ۹۰٪ شرکتهای NLP استفاده میشود.
training loop، custom dataset، DataLoader. برای fine-tuning و ساخت مدلهای اختصاصی ضروری است.
tokenization، lemmatization، stopword removal، text normalization برای فارسی (Hazm) و عربی.
Word2Vec، GloVe، FastText — پایههای pre-transformer که هنوز در بعضی use case های production مفیدند.
Pinecone، Weaviate، Chroma — برای semantic search و RAG pipeline ضروری شدهاند.
روشهای parameter-efficient fine-tuning که بدون GPU گرانقیمت، مدلهای بزرگ را customize میکنند.
مهارتهای نرم
معیارهای عددی (F1، BLEU، ROUGE) کافی نیستند. باید error analysis کرد، نمونههای اشتباه را دید و bias مدل را شناسایی کرد.
مهندس NLP باید بتواند «میخواهیم chatbot داشته باشیم» را به task مشخص (intent detection، entity extraction، response generation) تبدیل کند.
طراحی دستورالعمل annotation، آموزش annotator، بررسی inter-annotator agreement — بخشی از کار NLP است که اغلب نادیده گرفته میشود.
دانش حوزهای
BLEU (ترجمه)، ROUGE (خلاصه)، F1 (NER و classification)، Perplexity (language model). انتخاب معیار مناسب برای task مهم است.
NER، POS Tagging، Question Answering، Summarization، Machine Translation، Sentiment Analysis — هرکدام چالشهای خاص خود را دارند.
BPE، WordPiece، SentencePiece — هر مدل tokenizer متفاوتی دارد. برای زبانهای غیرانگلیسی، tokenizer مناسب حیاتی است.
ترکیب LLM با knowledge base اختصاصی — یکی از داغترین pattern های NLP در production امروز.
نقشه راه و مسیر آموزشی
نقشه راه تبدیل شدن به مهندس پردازش زبان طبیعی
این مسیر گام به گام شما را از صفر تا حرفهای هدایت میکند.
پایههای Python و پردازش متن
ابزارهای اولیه NLP و Python
منابع پیشنهادی
یادگیری ماشین برای متن
از Bag-of-Words تا Word Embeddings
Transformer و HuggingFace
اکوسیستم مدرن NLP
LLM و RAG
کار با مدلهای زبانی بزرگ
منابع پیشنهادی
Production و تخصص
استقرار مدلهای NLP در production
منابع پیشنهادی
ابزارها و استک فنی
ابزارهایی که هر مهندس AI باید بشناسد، دستهبندیشده بر اساس اولویت
کتابخانههای اصلی NLP
LLM و RAG
مسیر پیشرفت شغلی
از جونیور تا Staff Engineer — چه مهارتهایی نیاز دارید و چه درآمدی انتظار داشته باشید
جونیور NLP Engineer
۰-۲ سال
~$105K
میانگین سالانه (آمریکا)
fine-tuning مدلهای موجود، preprocessing، ارزیابی با معیارهای استاندارد
میدلول NLP Engineer
۲-۵ سال
~$162K
میانگین سالانه (آمریکا)
طراحی pipeline، RAG، LLM fine-tuning، deployment
سینیور NLP Engineer
۵-۱۰ سال
~$220K
میانگین سالانه (آمریکا)
معماری سیستم NLP، هدایت تیم، تصمیمگیری فنی
Staff / Principal NLP Engineer
۱۰+ سال
~$300K
میانگین سالانه (آمریکا)
تعریف direction فنی سازمان، cross-team leadership
چالشها و جنبههای منفی
واقعیتهایی که کمتر در آگهیهای شغلی میبینید — قبل از ورود بدانید
Hallucination در مدلهای زبانی
عمومیمدلهای زبانی بزرگ گاهی اطلاعات کاملاً نادرست را با اطمینان بیان میکنند. ساخت سیستمهای NLP reliable که hallucinate نکنند — بهخصوص در حوزههای حساس مثل پزشکی و حقوقی — چالش فنی اصلی امروز است.
کمبود داده فارسی و زبانهای کممنبع
استارتاپبرای انگلیسی میلیاردها token داده training وجود دارد. برای فارسی، دهها مرتبه کمتر. Fine-tuning مدلهای چندزبانه (mBERT، XLM-R) روی دادههای فارسی و مدیریت code-switching (ترکیب فارسی و انگلیسی) چالش خاص بازار ایرانی است.
ارزیابی واقعی کیفیت زبان
تحقیقاتیمعیارهای خودکار مثل BLEU با واقعیت فاصله دارند. یک ترجمه ممکن است BLEU پایینی داشته باشد اما از نظر انسانی بهتر باشد. طراحی evaluation که واقعاً کیفیت انسانی را اندازه بگیرد، مشکل حلنشده حوزه است.
Bias در دادههای آموزشی
شرکت بزرگمدلهای NLP bias های موجود در متن اینترنت را یاد میگیرند — تبعیض جنسیتی، نژادی و فرهنگی. شناسایی، اندازهگیری و کاهش این bias بدون آسیب به performance مدل، یکی از چالشهای اخلاقی حوزه است.
هزینه inference مدلهای بزرگ
استارتاپاجرای GPT-4-scale models در production گران است. برای استارتاپها، انتخاب بین مدل بزرگ با کیفیت بالا و مدل کوچکتر با هزینه کمتر، تصمیم بزرگ معماری است. quantization، distillation و caching راهحلهای ناقصی هستند.
حقوق و بازار کار جهانی
حقوق جهانی مهندس پردازش زبان طبیعی
میانگین حقوق سالانه بر اساس تجربه در کشورهای مختلف
| کشور | میانه | ارز |
|---|---|---|
🇺🇸ایالات متحده (سینیور) | $260,000 | USD |
* ارقام سالانه و تقریبی هستند و بر اساس میانگین بازار در سال ۲۰۲۵ محاسبه شدهاند.
چگونه از صفر شروع کنیم
برنامه گامبهگام برای ورود به مهندسی هوش مصنوعی
Python و پایههای پردازش متن
regex، string manipulation، NLTK برای tokenization پایه. یاد بگیر متن خام را تمیز کنی، tokenize کنی و برای مدل آماده کنی. برای فارسی، Hazm را یاد بگیر.
HuggingFace و اولین fine-tuning
یک مدل BERT را برای sentiment analysis روی dataset فارسی fine-tune کن. از Google Colab استفاده کن — رایگان و کافی است. هدف: اولین مدل کار با dataset واقعی.
ساخت یک classifier متن کامل
یک سیستم دستهبندی اخبار یا تحلیل احساسات توییتر بساز. از preprocessing تا deploy در HuggingFace Spaces. این پروژه اولیه portfolio است.
پروژههای پیشنهادی برای رزومه
تحلیل احساسات فارسی
مبتدیParsBERT را برای sentiment analysis توییتهای فارسی fine-tune کن. Dataset جمعآوری کن، annotation کن و مدل را در HuggingFace Spaces deploy کن.
Q&A روی اسناد فارسی با RAG
متوسطیک سیستم بساز که از روی PDF های فارسی جواب سوال میدهد. از LangChain، Chroma و یک LLM مثل Llama-3 فارسی استفاده کن.
NER (استخراج موجودیت) از اخبار فارسی
متوسطمدلی بساز که اسم افراد، مکانها و سازمانها را از خبر فارسی استخراج کند. Dataset اختصاصی annotation کن یا از PEYMA استفاده کن.
LLM فارسی اختصاصی با LoRA
پیشرفتهیک مدل Llama یا Mistral را با LoRA روی دادههای فارسی (اخبار، ادبیات، چت) fine-tune کن و ارزیابی معنایی انجام بده.
مثالهای واقعی و Case Studies
داستانهای واقعی از مهندسانی که در این حوزه تأثیرگذار بودهاند
از MIT فارغالتحصیل شد. ۸ سال استارتاپ ساخت. نمره B-minus در جبرخطی گرفت. در ۳۰ سالگی تصمیم گرفت AI یاد بگیرد — از صفر، بدون مدرک دکترا.
در ۶ ماه خودآموزی در South Park Commons، مهارت ML گرفت. به OpenAI پیوست و نویسنده اصلی GPT-3 شد — مدلی که اثبات کرد LLM میتواند few-shot task های مختلف را بدون fine-tuning حل کند. بعداً Anthropic را co-found کرد.
سن و مدرک دکترا مانع نیستند. ۶ ماه یادگیری فشرده و متمرکز میتواند درِ شرکتهای top AI را باز کند — اگر با project های واقعی همراه باشد.
Jacob Devlin
دانشجوی CS در دانشگاه Maryland. در Microsoft Research روی ترجمه ماشینی کار کرد و بعد به Google Brain پیوست.
در ۲۰۱۸ نویسنده اصلی BERT شد — مدلی که با pre-training bidirectional روی Wikipedia و Books Corpus، state of the art را در ۱۱ task مختلف NLP بهطور همزمان شکست. BERT پایه اکثر مدلهای NLP امروز است.
بزرگترین breakthrough ها اغلب از ترکیب ایدههای قبلی میآیند. BERT از Transformer (2017) + self-supervised learning + bidirectional context ساخته شد.
Ashish Vaswani
مهندس تحقیقات در Google Brain. روی ترجمه ماشینی کار میکرد و از محدودیتهای RNN در پردازش موازی ناراضی بود.
نویسنده اصلی «Attention is All You Need» (2017) — معماری Transformer که اساس تمام مدلهای زبانی بزرگ مدرن (BERT، GPT، T5) است. این paper یکی از ۵ مقاله تأثیرگذار دهه ۲۰۱۰ در AI است.
گاهی بزرگترین breakthrough از حذف پیچیدگی میآید نه اضافه کردن آن. Transformer با حذف RNN و جایگزینی با Attention محض، هم سادهتر و هم بهتر بود.
نمونه آگهی استخدام واقعی + تحلیل
یک آگهی واقعی از شرکت فعال در حال استخدام، با تحلیل هر بخش
Staff Software Engineer, Natural Language Processing
تحلیل نیازمندیها
5 years of experience with Natural Language Processing concepts and algorithms
Google برای Staff Engineer (که بالاتر از Senior است) سابقه طولانی میخواهد. «NLP concepts» یعنی باید tokenization، language model، sequence labeling، generation و evaluation را عمیق بدانی — نه فقط API call.
ضروری5 years of experience leading ML design and optimizing ML infrastructure
Staff = leadership. نه فقط کد بنویسی — باید تصمیم معماری بگیری، تیم را هدایت کنی و infrastructure را بهینه کنی. این نشان میدهد مهندس NLP ارشد باید system design را هم بداند.
ضروریExperience designing NLP solutions and training/evaluation pipelines for LLMs
LLM pipeline یعنی: data collection → preprocessing → pretraining/fine-tuning → evaluation → deployment. باید همه مراحل را هدایت کرده باشی. حتی تجربه با یک مرحله بهصورت عمیق، ارزشمند است.
ضروریProvide technical leadership on high-impact projects
Staff Engineer در Google بهعنوان technical lead روی پروژههایی که product واقعی دارند کار میکند — نه پروژههای تحقیقاتی صرف. این یعنی باید با PM، Design و Backend هم کار کنی.
مهمFacilitate alignment and clarity across teams on goals, outcomes, and timelines
در Google، بخش زیادی از کار Staff Engineer ارتباط و alignment است نه کد. باید بتوانی تیمهای مختلف را همراستا کنی — مهارتی که اغلب در curriculum دانشگاهی وجود ندارد.
مفیدتحلیل مسئولیتها
Design, develop, test, deploy, maintain, and enhance large-scale NLP solutions
چرخه کامل مسئولیت در Google: از ایده تا maintenance. یعنی وقتی مدلی میسازی، مسئول آن در production هم هستی. on-call rotation برای سیستمهای NLP بخشی از کار است.
Influence and coach a distributed team of engineers
Google تیمهای توزیعشده در چندین timezone دارد. باید async leadership را بلد باشی — مستندسازی خوب، تصمیمگیری واضح و feedback بدون face-to-face.
Manage project priorities, deadlines, and deliverables
Google به مهندس Staff Engineer اعتماد میکند که roadmap خودش را مدیریت کند. بدون PM مستقیم در هر تیم، مهندس باید prioritization را یاد بگیرد.
نتیجهگیری کلی
Google برای Staff NLP Engineer ترکیبی از technical depth (معماری LLM، pipeline کامل) و leadership (هدایت تیم، alignment) میخواهد. اگر میخواهی در این مسیر بروی، علاوه بر NLP، باید system design، technical writing و cross-functional collaboration را جدی بگیری.
آینده و روندها
پیشبینی ۵–۱۰ ساله و مهارتهایی که باید یاد بگیرید
اشتغال مهندسان NLP تا ۲۰۳۵ رشد ۳۶٪ خواهد داشت — سالانه ۲۰,۸۰۰ موقعیت شغلی جدید
منبع: US Bureau of Labor Statistics / JobzMall Career Outlook 2025
مهارتهای نوظهور که باید یاد بگیرید
پیشبینیهای آینده
اکثر محصولات دیجیتال از NLP به عنوان لایه اصلی تعامل کاربر استفاده میکنند. «جستجوی سنتی» در حال جایگزینی با conversational search است.
مدلهای اختصاصی domain (پزشکی، حقوقی، مالی) از مدلهای عمومی پیشی میگیرند. تقاضا برای NLP متخصص حوزهای به شدت رشد میکند.
NLP فارسی و عربی به بلوغ میرسد — شرکتهای منطقه خاورمیانه سرمایهگذاری جدی میکنند. متخصصان NLP فارسیزبان موقعیت رقابتی منحصربهفردی خواهند داشت.
مرز بین NLP، Computer Vision و Speech بهکلی از بین میرود. همه Language AI Engineers خواهند بود. حقوق median برای این نقش در آمریکا به $250k+ میرسد.
بزرگترین ریسک برای مهندس NLP، وابستگی بیش از حد به API های LLM است. اگر فقط بلدی از OpenAI API استفاده کنی، بهراحتی قابل جایگزینی هستی. مهندسانی که درک عمیق از معماری مدل، fine-tuning و evaluation دارند، ارزش بیشتری خواهند داشت. در عین حال، با multimodal شدن مدلها، «مهندس NLP» به «مهندس Language AI» تبدیل میشود — شامل تصویر، صدا و ویدیو.
ویدیوهای آموزشی
یک روز در زندگی یک NLP Engineer
ویدیوهای واقعی از متخصصان این حوزه که روزانه چه کارهایی انجام میدهند

Natural Language Processing Used for Improving Future Machine Learning Outcomes
DataCatchup

What Will Change In Data Science Project Development After OPENAI And Hugging Face API
Krish Naik
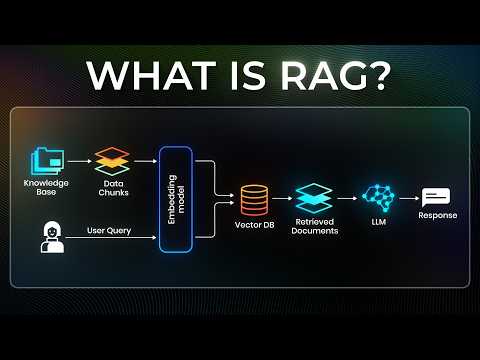
RAG Explained For Beginners
KodeKloud

Generative AI Explained In 5 Minutes | What Is GenAI? | Introduction To Generative AI | Simplilearn
Simplilearn
![[NLP][Computer Vision] Text and image classification in single model](/_next/image?url=https%3A%2F%2Fi.ytimg.com%2Fvi%2F-pA5nqzBcGA%2Fhqdefault.jpg&w=3840&q=75)
[NLP][Computer Vision] Text and image classification in single model
TechWithSherri

Reinforcement Learning from Human Feedback (RLHF) Explained
IBM Technology