
مهندس مدلهای زبانی بزرگ
LLM Engineer
مهندس LLM با مدلهای زبانی بزرگ مثل GPT-4، Claude، Llama و Mistral کار میکند — آنها را fine-tune، بهینه و در production مستقر میکند. با رشد بازار LLM از ۴.۵ به ۸۲ میلیارد دلار تا ۲۰۳۳ (CAGR 33.7٪) و میانگین حقوق ۲۰۶,۰۰۰ دلار، این داغترین تخصص هوش مصنوعی در ۲۰۲۵ است.
مقدمه و تعریف شغل
مهندس LLM (Large Language Model Engineer) متخصصی است که مدلهای زبانی بزرگ پیشآموزشدیده را برای کاربردهای خاص سازگار، بهینه و مستقر میکند. برخلاف مهندس DL که مدل را از صفر میسازد، مهندس LLM روی لایه application قرار دارد: fine-tuning، RAG، agent، evaluation و production.
تا ۲۰۲۲ LLM فقط در آزمایشگاههای بزرگ وجود داشت. انتشار ChatGPT در نوامبر ۲۰۲۲ و بعد از آن Llama (open-source Meta) در فوریه ۲۰۲۳ همه چیز را تغییر داد. ناگهان هر شرکتی میخواست chatbot، search assistant یا document analyzer داشته باشد. نقش «LLM Engineer» که قبل از ۲۰۲۳ وجود خارجی نداشت، تبدیل به یکی از پرتقاضاترین عناوین شغلی صنعت شد.
چه چیزی میسازید؟
مثالهای واقعی از خروجی کار یک مهندس مدلهای زبانی بزرگ
چتبات و دستیار هوشمند
دستیار داخلی شرکت، customer support bot، HR assistant
سیستم Q&A روی اسناد
RAG روی knowledge base، جستجو در قراردادهای حقوقی
LLM اختصاصی Domain
مدل پزشکی fine-tune شده، LLM کد فارسی، مدل حقوقی
AI Agent
عامل که web search، code execution و tool calling میکند
پلتفرم ارزیابی LLM
سیستم benchmark و red-teaming برای سنجش دقت و safety مدل
تخصصهای مختلف مهندس مدلهای زبانی بزرگ
این شغل یک عنوان واحد نیست — مسیرهای تخصصی متعددی دارد
متخصص fine-tuning
LLM Fine-tuning Specialist
تخصص در LoRA، QLoRA، RLHF، DPO — ساخت مدلهای domain-specific
معمار RAG
RAG Architect
طراحی سیستمهای Q&A روی document — retrieval، reranking، generation
مهندس عملیات LLM
LLM Ops Engineer
serving، caching، monitoring و cost optimization مدلها در production
توسعهدهنده ایجنت AI
AI Agent Developer
ساخت ایجنتهای multi-step که tool calling، planning و memory دارند
تفاوت با شغلهای مشابه
کجا این شغل تمام میشود و شغل دیگری شروع میشود؟
مهندس NLP طیف گستردهتری از task ها (NER، classification، translation) را با مدلهای کوچکتر هم پوشش میدهد. مهندس LLM فقط با مدلهای بزرگ ۷B+ parameter کار میکند و تمرکزش روی fine-tuning، prompting و deployment آنهاست.
AI Product Engineer بیشتر به integration و UX تمرکز دارد — چطور LLM را در محصول embed کنی. مهندس LLM عمیقتر است: مدل را میشناسد، failure mode را میداند، fine-tune میکند و evaluation میسازد.
Prompt Engineer فقط روی نوشتن prompt کار میکند. مهندس LLM کل stack را میپوشاند: از انتخاب مدل و fine-tuning تا RAG، evaluation و production deployment.
تأثیر در صنایع مختلف
مهندس مدلهای زبانی بزرگ در همه صنایع مشغول به کار است — نه فقط شرکتهای فناوری
حقوقی
LLM روی corpus قانونی fine-tune شده — بررسی قرارداد در دقیقه نه روز
مالی
تحلیل گزارش مالی، summarization اخبار بازار، compliance checking
پزشکی
مدلهای LLM برای clinical note، discharge summary، medical Q&A
آموزش
tutor هوشمند، تولید سوال آزمون، بازخورد شخصیسازیشده به دانشآموز
نرمافزار
code generation، code review، test writing — GitHub Copilot و جانشینانش
تصورات غلط رایج
قبل از تصمیمگیری، این باورهای اشتباه را بشناسید
LLM Engineer فقط از ChatGPT API استفاده میکند
استفاده از API فقط ابتداییترین کار است. مهندس LLM واقعی مدل را fine-tune میکند، evaluation benchmark میسازد، RAG pipeline طراحی میکند، latency را بهینه میکند و hallucination را کاهش میدهد.
باید دکترا داشته باشی
Anthropic صراحتاً میگوید PhD الزامی نیست — ۵۰٪ از تیم فنیشان دکترا ندارند. اگر project اختصاصی داشته باشی، به open-source کمک کرده باشی یا blog post فنی نوشته باشی، اینها در resume بالاتر از مدرک مینشینند.
LLM Engineer زود obsolete میشود چون مدلها بهتر میشوند
هر چه مدلهای پایه بهتر شوند، نیاز به مهندس برای fine-tuning، adaptation و deployment آنها بیشتر میشود. gap بین مدل عمومی و نیاز domain-specific هیچوقت بسته نمیشود.
یک روز کاری واقعی
در هر سطح روز کاری چه شکلی است؟
جونیور
کار با LLM API های موجود، ساخت RAG pipeline های ساده، آزمایش prompt ها و ارزیابی خروجی. بخش زیادی از روز صرف iteration روی prompt و تست میشود.
- ◆ساخت RAG pipeline با LangChain و Chroma
- ◆آزمایش prompt های مختلف و مقایسه نتایج
- ◆ارزیابی خروجی مدل با معیارهای کیفی
- ◆پیادهسازی streaming response
- ◆debug کردن context window overflow
میدلول
طراحی pipeline های پیچیدهتر، fine-tuning مدلهای open-source، ساخت evaluation framework، بهینهسازی هزینه inference.
- ◆fine-tuning Llama-3 با LoRA روی data اختصاصی
- ◆طراحی reranking pipeline برای RAG
- ◆ساخت LLM evaluation با LLM-as-judge
- ◆بهینهسازی prompt برای کاهش token cost
- ◆پیادهسازی multi-turn conversation با memory
سینیور
تعریف استراتژی LLM شرکت، تصمیمگیری build vs API vs fine-tune، طراحی evaluation که واقعاً کیفیت را اندازه میگیرد، هدایت تیم.
- ◆تعریف roadmap LLM platform شرکت
- ◆ارزیابی foundation model های مختلف برای use case
- ◆طراحی RLHF pipeline برای alignment
- ◆هدایت تیم در ساخت evaluation benchmark
- ◆همکاری با legal درباره data privacy LLM
مسئولیتها و وظایف
مسئولیتهای اصلی
وظایف روزانه و مهارتهای مورد نیاز در این شغل
- ◈طراحی و پیادهسازی pipeline fine-tuning مدلهای زبانی برای domain اختصاصی
- ◈ساخت سیستمهای RAG و Q&A روی knowledge base شرکت
- ◈ارزیابی کیفیت LLM با benchmark های اختصاصی و LLM-as-judge
- ◈بهینهسازی inference cost و latency در production
- ◈طراحی AI Agent با قابلیت tool calling و multi-step reasoning
- ◈پایش مدلها در production و رفع مشکلات hallucination و drift
- ◈مستندسازی prompt، data pipeline و تصمیمات فنی
- ◈همکاری با تیم product برای تعریف use case های LLM
مهارتهای مورد نیاز
مهارتهای فنی، نرم و حوزهای که یک مهندس مدلهای زبانی بزرگ موفق به آنها نیاز دارد
مهارتهای فنی
پایه همه کار LLM. PyTorch برای fine-tuning، HuggingFace برای model loading و training.
روشهای parameter-efficient که بدون GPU ۸۰GB، مدلهای ۷B-70B را fine-tune میکنند. LoRA یا QLoRA در ۹۰٪ پروژههای fine-tuning استفاده میشود.
Retrieval Augmented Generation — ترکیب LLM با knowledge base اختصاصی. embedding، vector search، reranking، context assembly.
فریمورکهای اصلی ساخت LLM application. LangChain برای agent و chain، LlamaIndex برای RAG.
Chroma، Pinecone، Weaviate، Qdrant — پایگاه داده embedding برای semantic search در RAG.
Few-shot، Chain-of-Thought، ReAct، structured output — نوشتن prompt که رفتار مدل را قابل پیشبینی کند.
روشهای alignment مدل با preference human — پشت ChatGPT و Claude. TRL library برای پیادهسازی.
vLLM، TGI (Text Generation Inference)، Ollama — serving مدلهای open-source در production با latency پایین.
مهارتهای نرم
معیارهای عددی (BLEU، ROUGE) برای LLM ناکافیاند. باید بدانی چطور quality را با LLM-as-judge، human eval و domain expert ارزیابی کنی.
آشنایی با failure mode های LLM: hallucination، prompt injection، bias. Anthropic میگوید این مهارت از PhD مهمتر است.
کِی باید از GPT-4 API استفاده کنی، کِی Llama fine-tune کنی، کِی distillation انجام دهی. این تصمیمگیری مهارت تجربی است.
دانش حوزهای
attention mechanism، KV cache، context window، tokenization. درک این مفاهیم برای debugging و optimization ضروری است.
GPTQ، AWQ، bitsandbytes — فشرده کردن مدل برای اجرا روی GPU های محدود. INT4 مدل ۷B را روی RTX 3090 اجرا میکند.
RAGAS برای RAG، MT-Bench، Evals (OpenAI) — ابزارهای ارزیابی systematic که کیفیت مدل را اندازه میگیرند.
cost per token، context length vs quality trade-off، caching strategy — هر call به GPT-4 هزینه دارد. بهینهسازی cost در production مهارت ارزشمندی است.
نقشه راه و مسیر آموزشی
نقشه راه تبدیل شدن به مهندس مدلهای زبانی بزرگ
این مسیر گام به گام شما را از صفر تا حرفهای هدایت میکند.
پایههای Python و LLM API
شروع با API های LLM و مفاهیم پایه
منابع پیشنهادی
RAG و LangChain
ساخت سیستمهای Q&A هوشمند
منابع پیشنهادی
Fine-tuning مدلهای Open-source
ساخت مدلهای اختصاصی
منابع پیشنهادی
AI Agent و LLM Deployment
ساخت agent و استقرار production
منابع پیشنهادی
Alignment و تخصص
RLHF، safety و open-source contribution
منابع پیشنهادی
ابزارها و استک فنی
ابزارهایی که هر مهندس AI باید بشناسد، دستهبندیشده بر اساس اولویت
مدلها و API
Fine-tuning و Training
مسیر پیشرفت شغلی
از جونیور تا Staff Engineer — چه مهارتهایی نیاز دارید و چه درآمدی انتظار داشته باشید
جونیور LLM Engineer
۰-۲ سال
~$110K
میانگین سالانه (آمریکا)
RAG pipeline، prompt engineering، LLM API integration
میدلول LLM Engineer
۲-۵ سال
~$175K
میانگین سالانه (آمریکا)
fine-tuning، agent، evaluation framework، cost optimization
سینیور LLM Engineer
۵-۱۰ سال
~$265K
میانگین سالانه (آمریکا)
RLHF pipeline، platform LLM، هدایت تیم
Staff / Principal Engineer
۱۰+ سال
~$380K
میانگین سالانه (آمریکا)
direction فنی سازمان، foundation model strategy
چالشها و جنبههای منفی
واقعیتهایی که کمتر در آگهیهای شغلی میبینید — قبل از ورود بدانید
Hallucination — مدل اطلاعات غلط با اطمینان بیان میکند
عمومیLLM ها میتوانند اطلاعات کاملاً ساختگی را با اطمینان بالا بیان کنند. در حوزههای حساس مثل پزشکی و حقوقی، این میتواند خطرناک باشد. RAG، grounding و evaluation pipelineهای دقیق تنها راهحلهای ناقصی هستند.
Context Window و اطلاعات طولانی
عمومیمدلها context window محدودی دارند. وقتی document طولانی است، باید chunk کنی، اما مهمترین اطلاعات ممکن است در میانه document باشد که مدل آن را «فراموش» میکند (Lost-in-the-Middle problem).
هزینه inference در مقیاس
استارتاپGPT-4 برای ۱ میلیون کاربر، هزینهای میشود که استارتاپ را ورشکست میکند. migration از API به open-source self-hosted، distillation به مدل کوچکتر، یا prompt optimization از جمله کارهایی است که مهندس LLM انجام میدهد.
Prompt Injection و Security
شرکت بزرگکاربر میتواند با prompt خاص، system prompt را override کند یا مدل را به انجام کارهای ناخواسته وادارد. defense در برابر prompt injection هنوز یک مشکل حلنشده است.
ارزیابی کیفیت واقعی مدل
تحقیقاتیچطور بفهمی LLM fine-tune شدهات واقعاً بهتر است؟ معیارهای کمی ناکافیاند. ساخت evaluation benchmark معنادار — که با نظر انسانی و نیاز کسبوکار align باشد — یکی از سختترین چالشهاست.
حقوق و بازار کار جهانی
حقوق جهانی مهندس مدلهای زبانی بزرگ
میانگین حقوق سالانه بر اساس تجربه در کشورهای مختلف
| کشور | میانه | ارز |
|---|---|---|
🇺🇸ایالات متحده (سینیور) | $310,000 | USD |
* ارقام سالانه و تقریبی هستند و بر اساس میانگین بازار در سال ۲۰۲۵ محاسبه شدهاند.
چگونه از صفر شروع کنیم
برنامه گامبهگام برای ورود به مهندسی هوش مصنوعی
Python پایه و API های LLM
OpenAI API، Anthropic Claude API و HuggingFace را یاد بگیر. بفهم tokenization چیست، context window چطور کار میکند و چرا temperature مهم است. اولین chatbot ساده را بساز.
RAG Pipeline اول
با LangChain و Chroma یک سیستم Q&A بساز که روی PDF جواب میدهد. این پروژه مفاهیم embedding، vector search و prompt assembly را یاد میدهد.
Prompt Engineering سیستماتیک
few-shot، chain-of-thought، role-based prompting را با آزمایشهای کنترلشده یاد بگیر. PromptFoo یا LangSmith نصب کن تا prompt ها را ردیابی کنی.
پروژههای پیشنهادی برای رزومه
Q&A روی اسناد فارسی با RAG
مبتدییک سیستم بساز که از PDF های فارسی جواب میدهد. از LangChain، Chroma و Claude یا Llama فارسی استفاده کن. در HuggingFace Spaces deploy کن.
Fine-tuning مدل فارسی با LoRA
متوسطLlama-3.2 یا Mistral را با QLoRA روی dataset فارسی fine-tune کن. از dataset های عمومی (داستان، اخبار) استفاده کن. perplexity را قبل و بعد مقایسه کن.
AI Agent با Tool Calling
متوسطیک agent بساز که سوال دریافت میکند، web search میکند، محاسبه انجام میدهد و جواب ساختارمند میدهد. از LangGraph یا OpenAI function calling استفاده کن.
LLM Evaluation Benchmark فارسی
پیشرفتهیک benchmark بساز که LLM های مختلف را در فارسی ارزیابی کند — درک متن، استدلال، دانش فرهنگی. نتایج را در HuggingFace Space منتشر کن.
مثالهای واقعی و Case Studies
داستانهای واقعی از مهندسانی که در این حوزه تأثیرگذار بودهاند
Harrison Chase
فارغالتحصیل Harvard در رشته آمار. در Robust Intelligence روی ML کار کرد. در اواخر ۲۰۲۲، مشغول آزمایشهای شخصی با GPT-3 API بود.
در اکتبر ۲۰۲۲ LangChain را ساخت — فریمورکی که ساخت LLM application را سادهتر کرد. در عرض ۶ ماه، LangChain تبدیل به پرکاربردترین فریمورک LLM شد با ۷۵,۰۰۰ ستاره GitHub. شرکت در ۲۰۲۳ با ارزشگذاری $200M سرمایهگذاری گرفت.
بزرگترین تأثیر اغلب از ساختن ابزار برای دیگر مهندسان میآید نه از ساختن مدل. LangChain مشکل عملی را حل کرد: «چطور LLM را با بقیه سیستم وصل کنم؟»
مهندس نرمافزار معمولی. بدون background خاص ML. در ۲۰۲۴ تصمیم گرفت به تیمهای LLM بزرگ برود.
Rust یاد گرفت، ۱۵ pull request به پروژههای open-source (ruff و uv) merge کرد، یک paper تحقیقاتی نوشت. در اوایل ۲۰۲۵ offer از Mistral AI دریافت کرد — بدون PhD، فقط با کار عملی و مشارکت open-source.
کد در open-source از CV بهتر صحبت میکند. Anthropic و Mistral صراحتاً میگویند مشارکت open-source و blog post فنی را بالاتر از مدرک میبینند.
Sebastian Raschka
دکترای زیستشناسی محاسباتی. به ML علاقه داشت. کتابها و tutorials ساده و قابل فهم مینوشت.
نویسنده «Build a Large Language Model from Scratch» — که در سال ۲۰۲۴ پرفروشترین کتاب ML شد. Staff Research Engineer در Lightning AI. newsletter Machine Learning Q&A با ۱۰۰k+ مشترک.
آموزش دادن عمق درک را افزایش میدهد. وقتی مفهوم پیچیدهای را ساده توضیح میدهی، اطمینان مییابی که واقعاً میفهمی.
نمونه آگهی استخدام واقعی + تحلیل
یک آگهی واقعی از شرکت فعال در حال استخدام، با تحلیل هر بخش
Research Engineer — Fine-tuning & Alignment
تحلیل نیازمندیها
PhD and prior ML experience are NOT required
Anthropic یکی از نادر شرکتهای top AI است که این را صراحتاً میگوید. ۵۰٪ از تیم فنی دکترا ندارند. این نشانه تغییر فرهنگ صنعت است — production skill از publication مهمتر است.
مهمIndependent research, insightful blog posts, or substantial open-source contributions
Anthropic به اینها بیشتر از مدرک اهمیت میدهد. یک blog post فنی که ۱۰,۰۰۰ reader داشته باشد، یا یک feature merged در HuggingFace، بیشتر از GPA روی resume اثر میگذارد.
ضروریFamiliarity with Claude-style models, safety policies, and failure-mode thinking
Anthropic به مهندسانی نیاز دارد که نه فقط مدل را کار کنند، بلکه safety را در طراحی لحاظ کنند. red-teaming، robustness testing و thinking about edge cases بخشی از culture Anthropic است.
ضروریExperience with RLHF, DPO, or Constitutional AI techniques
Anthropic پیشگام RLHF و Constitutional AI است. اگر با TRL کار کردهای و reward model ساختهای، این advantage بزرگی است. حتی یک پروژه open-source RLHF در GitHub کمک میکند.
مهمStrong Python and PyTorch skills
بله، طبیعتاً. اما Anthropic بیشتر از کد تمیز و scalable، توانایی debugging مدلهای پیچیده را ارزیابی میکند — چون مشکلات alignment اغلب subtle و tricky هستند.
ضروریتحلیل مسئولیتها
Design and run fine-tuning experiments for alignment and capability improvement
loop سریع آزمایش: ایده → پیادهسازی → eval → iterate. در Anthropic این loop باید در ساعتها نه روزها انجام شود. codebase تمیز و modular برای reuse مهم است.
Build evaluation pipelines that capture safety and quality
در Anthropic، eval تنها به accuracy محدود نمیشود — باید harmlessness، honesty و helpfulness هم اندازه شود. ساخت benchmarkهایی که این ابعاد را capture کنند بخش اصلی کار است.
Contribute to Constitutional AI and RLAIF research
Constitutional AI رویکرد Anthropic برای alignment بدون انسان است — مدل بر اساس یک constitution خودش را evaluate میکند. اگر این مفهوم را میشناسی و روی آن کار کردهای، advantage بزرگی داری.
نتیجهگیری کلی
Anthropic به دنبال مهندسی است که هم کد عالی بنویسد هم درباره safety جدی فکر کند. PhD لازم نیست اما depth لازم است. اگر میخواهی در Anthropic باشی: RLHF را یاد بگیر، یک blog post فنی درباره alignment بنویس و به open-source کمک کن.
آینده و روندها
پیشبینی ۵–۱۰ ساله و مهارتهایی که باید یاد بگیرید
بازار LLM از ۴.۵ میلیارد دلار (۲۰۲۳) به ۸۲.۱ میلیارد دلار (۲۰۳۳) میرسد — CAGR 33.7٪
منبع: Grand View Research LLM Market Report 2024
مهارتهای نوظهور که باید یاد بگیرید
پیشبینیهای آینده
اکثر شرکتهای متوسط LLM اختصاصی fine-tune شده دارند. «LLM Engineer» تبدیل به یک نقش standard میشود مثل «Full-stack Developer».
مدلهای ۱B-3B کیفیتی میرسند که امروز GPT-4 دارد. مهندسانی که میتوانند این مدلهای کوچک را برای domain خاص fine-tune کنند، پرتقاضا میشوند.
AI Agent هایی که hفتهها کار میکنند بدون دخالت انسانی، واقعی میشوند. مهندسانی که long-horizon planning و multi-agent orchestration میدانند، premium میگیرند.
مرز بین LLM Engineer، Software Engineer و Product Engineer محو میشود. هر مهندس نرمافزار باید LLM integration بلد باشد. اما متخصصان fine-tuning و alignment همچنان نادر و گرانقیمت هستند.
بزرگترین ریسک برای مهندس LLM که فقط با API کار میکند، آسیبپذیری در برابر تغییرات pricing یا availability است. وقتی OpenAI سیاستش را تغییر میدهد، کل محصول در خطر است. مهندسانی که با open-source (Llama، Mistral) هم راحتاند، ریسک کمتری دارند. همچنین، ظهور multimodal models نشان میدهد مهندس LLM آینده باید text-only نباشد.
ویدیوهای آموزشی
یک روز در زندگی یک LLM Engineer
ویدیوهای واقعی از متخصصان این حوزه که روزانه چه کارهایی انجام میدهند
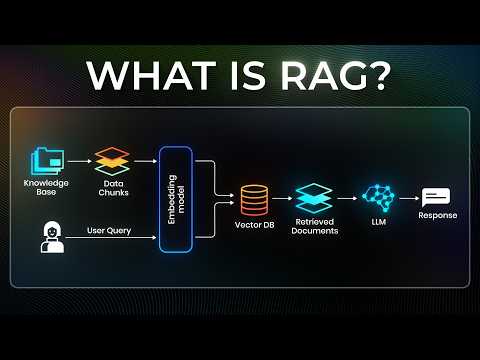
RAG Explained For Beginners
KodeKloud

LangChain Explained in 13 Minutes | QuickStart Tutorial for Beginners
Rabbitmetrics

LLMs — How ChatGPT works & What is RAG? | Retrieval-Augmented Generation Explained 🔥
CodeWithHarry

What is RAG ? | Completely Explained in 15 Minutes
Apna College

Reinforcement Learning from Human Feedback (RLHF) Explained
IBM Technology

Advanced RAG techniques for developers
Google Cloud Tech